Kria-PYNQのbaseを元に,オリジナルIPを組み込んだbitファイルを作成してPYNQから叩いてみることにします.ここでは対象のIPをVitis HLSを使って作成し,Jupyter NotebookのPythonノートブックからアクセスしてみました.
なお,$ROOTDIR は,Kria-PYNQをGitHubからcloneしたディレクトリを指します.
作業ディレクトリの用意
まずはIPをVitis HLSで作成するための作業ディレクトリを用意して,Vitis HLSを起動します.Vitis HLSはbaseのビルドに使った2020.2.2を利用します.
$ mkdir $ROOT/myipcore
$ cd $ROOT/myipcore
$ source /tools/Xilinx/Vitis/2020.2/settings64.sh
$ vitis_hlsプロジェクトの作成
いつもの手順でVitis HLSでプロジェクトを作成します.ちなみに,ターゲットボードとして Kria KV260 Vison AI Starter Kit を選択すると「XCK26-SFVC784-2LV-Cがみつからない」というようなエラーで,C Simulationからして失敗してしまいました.仕方ないので,似たようなデバイスということで xczu5ev-*-2 をを選択することに.ちゃんと2020.2.2のアップデートしたんだけどなあ.
コードの記述
プロジェクトのSourceに以下の内容の vector_add.c と vector_add.h を追加して以下の内容を記述します.
#include "vector_add.h"
void vector_add(int a[128], int b[128], int c[128]){
#pragma HLS INTERFACE s_axilite port=return
#pragma HLS INTERFACE s_axilite port=a
#pragma HLS INTERFACE s_axilite port=b
#pragma HLS INTERFACE s_axilite port=c
for(int i = 0; i < 128; i++){
c[i] = a[i] + b[i];
}
}#ifndef _VECTOR_ADD_H_
#define _VECTOR_ADD_H_
void vector_add(int a[128], int b[128], int c[128]);
#endif /* _VECTOR_ADD_H_ */Testbenchには,以下のような vector_add_tb.cを作成します.
#include <stdio.h>
#include "vector_add.h"
int main(int argc, char **argv){
int a[128];
int b[128];
int c[128];
int c_sw[128];
int i;
for(i = 0; i < 128; i++){
a[i] = i;
b[i] = i;
c[i] = 0;
c_sw[i] = a[i] + b[i];
}
vector_add(a, b, c);
for(i = 0; i < 128; i++){
if(c_sw[i] != c[i]){
printf("%d: expected %d, but the actual %d\n", i, c_sw[i], c[i]);
return 1;
}
}
return 0;
}ターゲット関数として,vector_add.c の vector_add を設定してコードの記述はおしまい.
IPコアの作成
C Simulation → C Synthesis → Co-Simulation → Export RTL とします.合成されたIPでは,関数の制御/ステータス信号および仮引数がすべて一つのAXI4-LiteなSlaveにまとめられます.メモリマップは次のように設定されていました.
//------------------------Address Info-------------------
// 0x000 : Control signals
// bit 0 - ap_start (Read/Write/COH)
// bit 1 - ap_done (Read/COR)
// bit 2 - ap_idle (Read)
// bit 3 - ap_ready (Read)
// bit 7 - auto_restart (Read/Write)
// others - reserved
// 0x004 : Global Interrupt Enable Register
// bit 0 - Global Interrupt Enable (Read/Write)
// others - reserved
// 0x008 : IP Interrupt Enable Register (Read/Write)
// bit 0 - enable ap_done interrupt (Read/Write)
// bit 1 - enable ap_ready interrupt (Read/Write)
// others - reserved
// 0x00c : IP Interrupt Status Register (Read/TOW)
// bit 0 - ap_done (COR/TOW)
// bit 1 - ap_ready (COR/TOW)
// others - reserved
// 0x200 ~
// 0x3ff : Memory 'a' (128 * 32b)
// Word n : bit [31:0] - a[n]
// 0x400 ~
// 0x5ff : Memory 'b' (128 * 32b)
// Word n : bit [31:0] - b[n]
// 0x600 ~
// 0x7ff : Memory 'c' (128 * 32b)
// Word n : bit [31:0] - c[n]
// (SC = Self Clear, COR = Clear on Read, TOW = Toggle on Write, COH = Clear on Handshake)IPの組み込み
IPを作ったらあらかじめビルドしておいた base のVivadoプロジェクト $ROOTDIR/kv260/base/base/base.xpr を開いて,IP Integrator でインスタンス生成してぶらさげます.
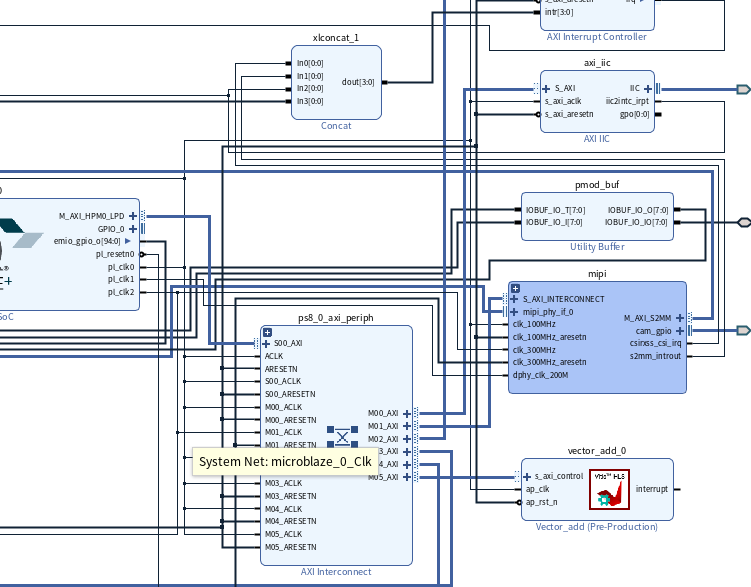
Vitis HLSを使って作成したIPを利用できるように $ROOTDIR/myipcore をIPカタログのリポジトリに追加したら,ここでは↓のように,vector_add_0 として,M_AXI_HPM0_LPD から制御される ps8_0_axi_periph なる AXI Interconnect の先にぶらさげます.
ビットファイルの作成とKV260への転送
Generate Bitstreamをクリックして,しばらく待つと,
- kv260/base/base/base.runs/impl_1/base_wrapper.bit
- kv260/base/base/base.gen/sources_1/bd/base/hw_handoff/base.hwh
ができます.できた2つのファイルをKV260に転送し,/home/root/jupyter_notebooks の下に mycoreディレクトリを作成して配置しておきます.
Jupyter Notebookで実行
あとは,Juypter環境でPythonから叩くだけ.
Jupyter Notebookのルートディレクトリが /home/root/jupyter_notebooks なので,Jupyter Notebookのルートディレクトリ直下にある mycore にPython3ノートを作る.
まずは,
from pynq import Overlay
base = Overlay("./myipcore.bit")
from pynq import MMIO
mmio = MMIO(base_addr=base.ip_dict['vector_add_0']['phys_addr'], length=0x1000, debug=True)として vector_add_0 へのハンドラ(メモリ領域へのアクセサ)を取得する.
mmio.read(0)とか実行するとIPの0番地の値が返ってくる.ap_idle に相当する 4 が返ってくる.
for i in range(128):
mmio.write(512+4<em>i, i)
mmio.write(1024+4</em>i, i)
mmio.write(1536+4<em>i, 0)として,仮引数の a, b, c に相当する領域を初期化した後,
mmio.write(0, 1)で,処理の実行を開始できます.処理はすぐに終わるはずです.
mmio.read(0)とすると,今度は ap_ready と ap_idle が立った状態の 6 が返ってきます.たしかに,Vitis HLSで生成した vector_add 関数相当のハードウェアが駆動されたことが分かります.
for i in range(128):
print(mmio.read(1536+4i))で,結果が格納されている c の先のメモリを読めます.
0
2
4
6
8
10
12
14
…と,a と b を足した値が c に格納されていて,正しく処理が実行できたことがわかります.