IntelがCPUでもGPUでもFPGAでも同じようにプログラミングできるOneAPIをはじめる、DevCloudで試すことができる、という話を聞いたのでためしてみました。
説明書は https://github.com/intel/FPGA-Devcloud にあるのですが、若干手順が分かりづらかったのでメモです。
DevCloudにアカウントを作る
DevCloudのレジストレーションサイト https://intelsoftwaresites.secure.force.com/devcloud/oneapi に必要な情報を入力してアカウントを作成。ログインに必要な情報がメールで届きます。
sshでログインできるようにする
JupyterLabでログインしてもいいのですが、sshの鍵を設定すればターミナルでログインできるようにもできる。
サインインして、1-CONNECT → Connect with a Terminal とたどる。
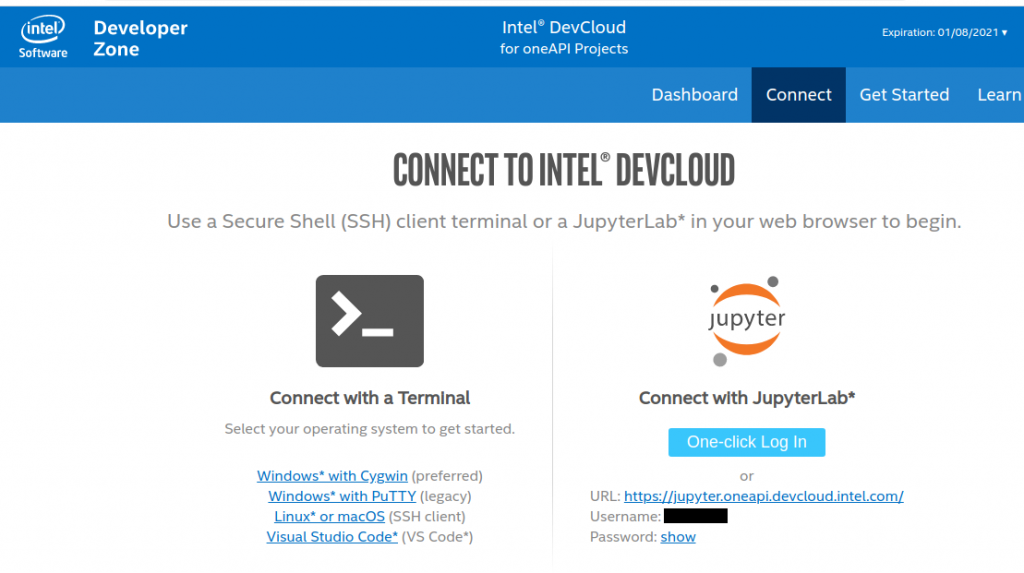
Connect with a Terminalにアクセスするとマニュアルにアクセスできる。ここで、setup-devcloud-access-*****.txt というファイルがダウンロードできるので、実行するとsshの設定をよろしくやってくれる。
設定が終わると、手元のPCから
$ ssh devcloudでログインできるようになる。
OneAPIを使ってみる
手順は、https://github.com/intel/FPGA-Devcloud/tree/master/main/QuickStartGuides/OneAPI_Program_PAC_Quickstart/Arria%2010 に書いてある…のだけど環境設定と叩くべきコマンドが少々分かりづらかった。
こんな感じで実行。
source /data/intel_fpga/devcloudLoginToolSetup.shこれでドキュメントにある devcloud_login コマンドが使えるようになる
******:~$ devcloud_login
You are selecting an interactive compute server sesssion. Please consider using batch mode submission using
devcloud_login -b to not tie up compute servers with idle sessions.
See the help menu using devcloud_login -h for more details.
What are you trying to use the Devcloud for?
1) Arria 10 PAC Compilation and Programming - RTL AFU, OpenCL
2) Arria 10 - OneAPI, OpenVINO
3) Stratix 10 PAC Compilation and Programming - RTL AFU, OpenCL
4) Compilation (Command Line) Only
5) Enter Specific Node Number
Number: 2
running: qsub -I -l nodes=s001-n081:ppn=2
qsub: waiting for job 695302.v-qsvr-1.aidevcloud to start
qsub: job 695302.v-qsvr-1.aidevcloud ready
########################################################################
# Date: Mon Sep 28 02:37:09 PDT 2020
# Job ID: 695302.v-qsvr-1.aidevcloud
# User: *******
# Resources: neednodes=s001-n081:ppn=2,nodes=s001-n081:ppn=2,walltime=06:00:00
########################################################################これで、FPGAが搭載されたサーバにログインできたことになってる、みたい。で、ツールのセットアップ
$ source /data/intel_fpga/devcloudLoginToolSetup.sh
$ tools_setupとするとツールの選択ができるので6のOneAPIを選択。
Which tool would you like to source?
1) Quartus Prime Lite
2) Quartus Prime Standard
3) Quartus Prime Pro
4) HLS
5) Arria 10 PAC Compilation and Programming - RTL AFU, OpenCL
6) Arria 10 - OneAPI, OpenVINO
7) Stratix 10 PAC Compilation and Programming - RTL AFU, OpenCL
Number: 6
sourcing /opt/intel/inteloneapi/setvars.sh
:: WARNING: setvars.sh has already been run. Skipping re-execution.
To force a re-execution of setvars.sh, use the '--force' option.
Using '--force' can result in excessive use of your environment variables.
[setupvars.sh] OpenVINO environment initialized作業環境を作成して、プロジェクト作成用のウィザードを開く
$ mkdir A10_ONEAPI
$ cd A10_ONEAPI/
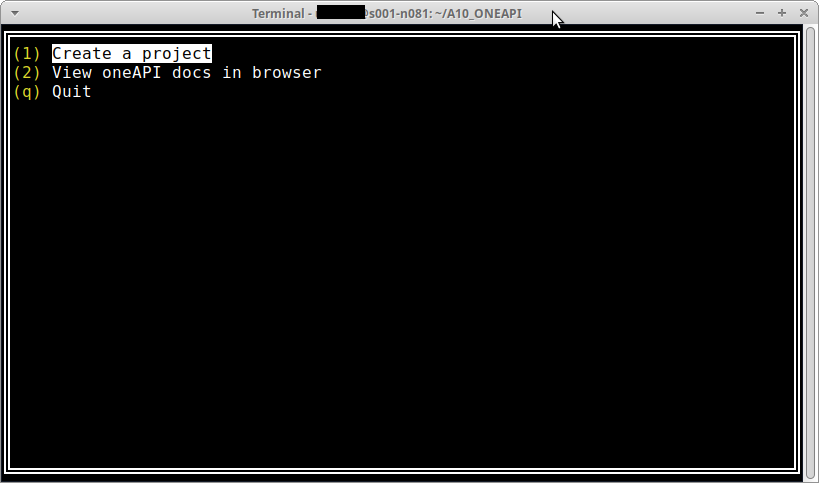
$ oneapi-cliここから、ターミナル上のUIでプロジェクトを作成。まず、Create a project でプロジェクトを作って
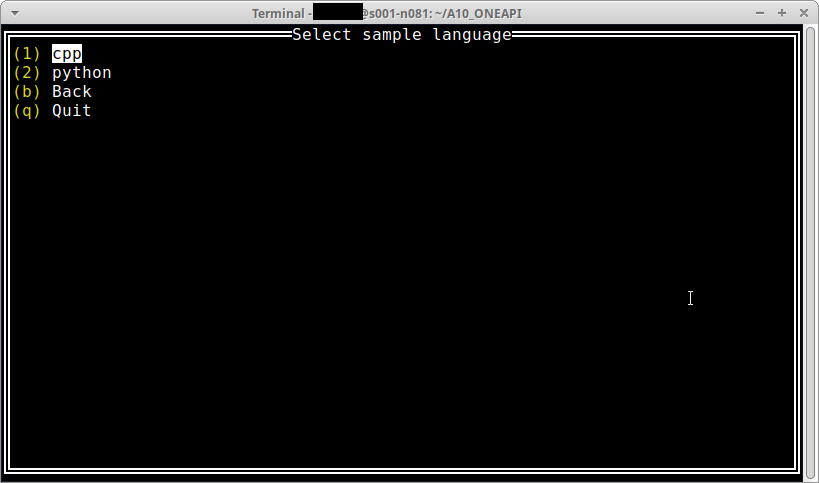
ドキュメントに従ってcppを選択。
Intel(R) oneAPI DPC++の下のC++ Compilerの下の”CPU, GPU and FPGA”の下の”Vector Add”を選択。
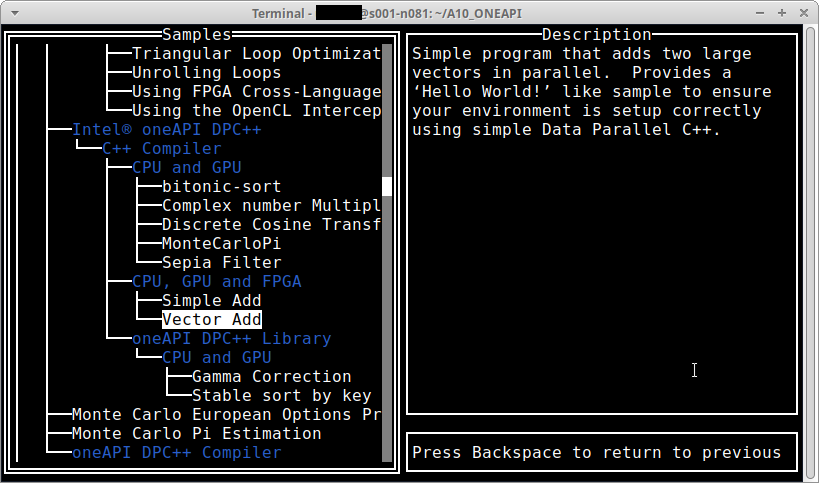
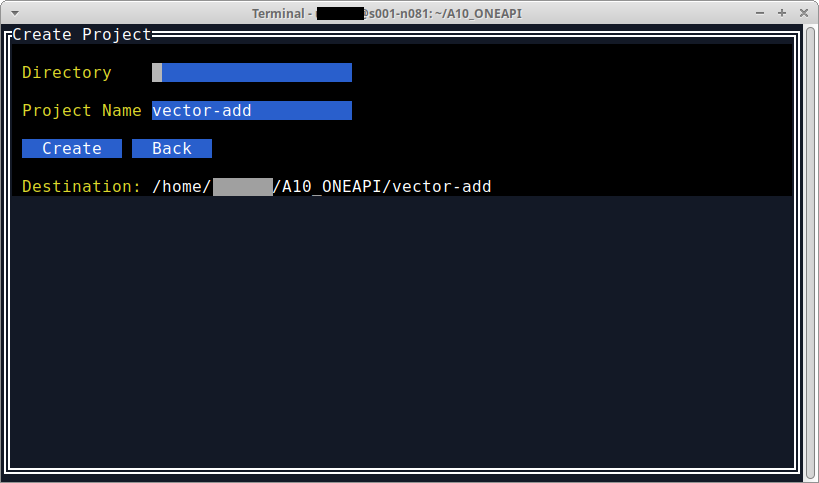
コマンドを実行したディレクトリ直下にプロジェクトを作成するので、Directoryの中身は空のままCreateを選択(タブでカーソルを移動する)。
確認画面。Quitで先にすすんでしまうことにする。
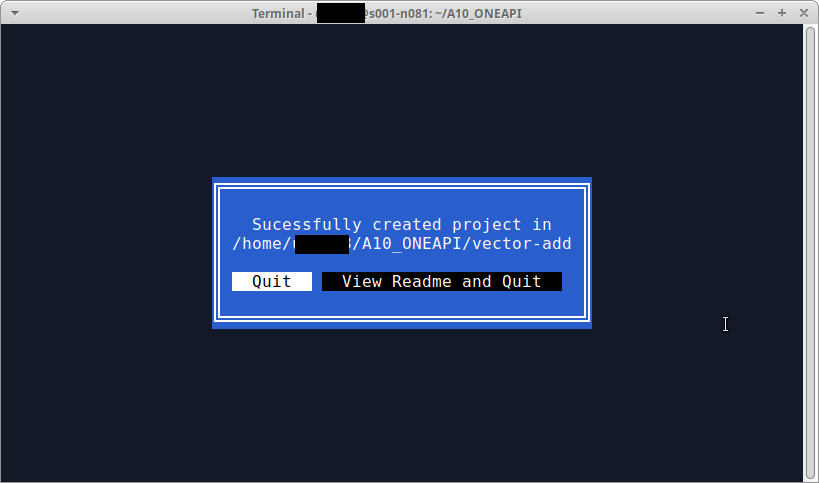
これで、サンプルプロジェクト vector-add がコマンドを実行した、$HOME/vector-add の下に作成されるので、移動
$ cd vector-addまずはエミュレータで実行
$ make run_emu -f Makefile.fpga
dpcpp -O2 -g -std=c++17 -fintelfpga src/vector-add-buffers.cpp -o vector-add-buffers.fpga_emu -DFPGA_EMULATOR=1
./vector-add-buffers.fpga_emu
Running on device: Intel(R) FPGA Emulation Device
Vector size: 10000
[0]: 0 + 0 = 0
[1]: 1 + 1 = 2
[2]: 2 + 2 = 4
…
[9999]: 9999 + 9999 = 19998
Vector add successfully completed on device.うまく実行できたっぽい。実機でも実行。
$ make run_hw -f Makefile.fpga
dpcpp -O2 -g -std=c++17 -fintelfpga -c src/vector-add-buffers.cpp -o a.o -DFPGA=1
dpcpp -O2 -g -std=c++17 -fintelfpga a.o -o vector-add-buffers.fpga -Xshardware
aoc: Compiling for FPGA. This process may take several hours to complete. Prior to
performing this compile, be sure to check the reports to ensure the design will meet your
performance targets. If the reports indicate performance targets are not being met,
code edits may be required. Please refer to the oneAPI FPGA Optimization Guide for
information on performance tuning applications for FPGAs.
Running on device: pac_a10 : Intel PAC Platform (pac_ee00000)
Vector size: 10000
[0]: 0 + 0 = 0
[1]: 1 + 1 = 2
[2]: 2 + 2 = 4
...
[9999]: 9999 + 9999 = 19998
Vector add successfully completed on device.実機でも同じように動作することがわかった。なお、timeコマンドで実行時間を測定した結果が次の通り。結構かかるなあ。
real 51m48.382s
user 239m9.249s
sys 6m48.382s動かしたコードのカーネル部分はこんな感じだった。
//************************************
// Vector add in DPC++ on device: returns sum in 4th parameter "sum_parallel".
//************************************
void VectorAdd(queue &q, const IntArray &a_array, const IntArray &b_array,
IntArray &sum_parallel) {
// Create the range object for the arrays managed by the buffer.
range<1> num_items{a_array.size()};
// Create buffers that hold the data shared between the host and the devices.
// The buffer destructor is responsible to copy the data back to host when it
// goes out of scope.
buffer a_buf(a_array);
buffer b_buf(b_array);
buffer sum_buf(sum_parallel.data(), num_items);
// Submit a command group to the queue by a lambda function that contains the
// data access permission and device computation (kernel).
q.submit([&](handler &h) {
// Create an accessor for each buffer with access permission: read, write or
// read/write. The accessor is a mean to access the memory in the buffer.
auto a = a_buf.get_access<access::mode::read>(h);
auto b = b_buf.get_access<access::mode::read>(h);
// The sum_accessor is used to store (with write permission) the sum data.
auto sum = sum_buf.get_access<access::mode::write>(h);
// Use parallel_for to run vector addition in parallel on device. This
// executes the kernel.
// 1st parameter is the number of work items.
// 2nd parameter is the kernel, a lambda that specifies what to do per
// work item. The parameter of the lambda is the work item id.
// DPC++ supports unnamed lambda kernel by default.
h.parallel_for(num_items, [=](id<1> i) { sum[i] = a[i] + b[i]; });
});
}実機情報を見てみるとこんな感じだった。
5e:00.0 Processing accelerators: Intel Corporation Device 09c4
Subsystem: Intel Corporation Device 0000
Control: I/O- Mem+ BusMaster+ SpecCycle- MemWINV- VGASnoop- ParErr+ Stepping- SERR+ FastB2B- DisINTx+
Status: Cap+ 66MHz- UDF- FastB2B- ParErr- DEVSEL=fast >TAbort- <TAbort- <MAbort- >SERR- <PERR- INTx-
Latency: 0, Cache Line Size: 32 bytes
Interrupt: pin A routed to IRQ 91
NUMA node: 0
Region 0: Memory at 38fffff00000 (64-bit, prefetchable) [size=512K]
Region 2: Memory at 38ffffe00000 (64-bit, prefetchable) [size=1M]
Capabilities: <access denied>
Kernel driver in use: intel-fpga-pci
Kernel modules: intel_fpga_pci